ItaEval e TweetyIta
- Giuseppe Attanasio
- Benchmark
- 4 aprile 2024
Table Of Contents
Nel panorama in rapida evoluzione dell’intelligenza artificiale e dell’elaborazione del linguaggio naturale, la community RiTA ha compiuto un passo significativo con lo sviluppo di due risorse innovative: TweetyIta, un modello linguistico efficiente, e ItaEval, un benchmark comprehensivo per la valutazione dei modelli linguistici italiani.
Questo sprint di ricerca nasce da un’ambiziosa collaborazione tra ricercatori e ricercatrici italiane e internazionali, uniti/e dall’obiettivo di migliorare la comprensione e la valutazione dei modelli linguistici per l’italiano. Il risultato è un progetto che va oltre i confini accademici tradizionali, dimostrando la forza della ricerca collaborativa. Si ringraziano: Pieter Delobelle, Moreno La Quatra, Giuseppe Attanasio, Andrea Santilli e Beatrice Savoldi.
TweetyIta: Efficienza e Innovazione
TweetyIta rappresenta un approccio innovativo nell’evoluzione dei modelli linguistici. La sua caratteristica distintiva è la tecnica di Trans-Tokenization, un metodo rivoluzionario che ottimizza l’elaborazione linguistica. Questa tecnica consente di adattare il modello con un’efficienza straordinaria, necessitando di sole 5G di token provenienti da corpora di italiano naturale per raggiungere prestazioni competitive.
Trans-Tokenization. La Trans-Tokenization è un approccio metodologico che ripensa il processo di tokenizzazione tradizionale. Invece di frammentare il testo in unità rigide, questa tecnica permette una trasformazione dinamica e contestuale dei token, massimizzando la comprensione linguistica con un investimento computazionale minimo.
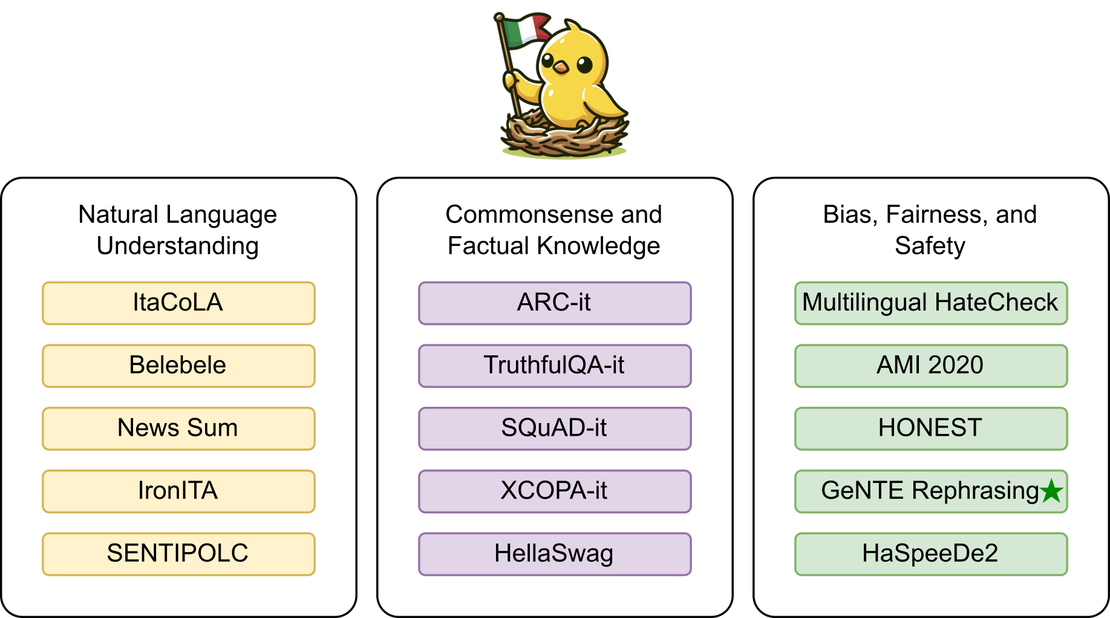
ItaEval: Un Benchmark Esteso
ItaEval si configura come un punto di riferimento cruciale per la valutazione dei modelli linguistici italiani. Il benchmark copre molteplici dimensioni:
- Comprensione del linguaggio
- Valutazione delle conoscenze fattuali e del senso comune
- Analisi dei bias sociali
Attraverso ItaEval, la community RiTA ha standardizzato un protocollo di valutazione che offre insights profondi sulle capacità attuali dei modelli linguistici.
Risultati preliminari. L’analisi condotta rivela alcuni risultati interessanti:
- Modelli addestrati prevalentemente su dati in Inglese dominano la classifica
- TweetyIta si dimostra competitivo rispetto ad altri modelli di adattamento
- I task di comprensione del linguaggio naturale si confermano particolarmente difficili
Riconoscimenti e Prospettive Future
TweetyIta e ItaEval saranno presentati alla conferenza CLIC-IT 2024, un palcoscenico prestigioso per la ricerca computazionale in Italia. Inoltre, ItaEval è diventato parte integrante del benchmark CALAMITA, un’iniziativa supportata da AILC che rafforza ulteriormente il suo impatto nel panorama della ricerca linguistica.
Accesso Aperto
Fedeli ai principi di trasparenza e collaborazione scientifica, il codice e i dati sono stati resi disponibili pubblicamente su GitHub e una leaderboard live è ospitata su HuggingFace.