ITALIC
- Giuseppe Attanasio
- Dataset
- 4 aprile 2022
Table Of Contents
Le risorse in lingua italiana per l’elaborazione del linguaggio naturale, sia in forma testuale che in forma di registrazioni audio, sono ancora limitate rispetto a quelle disponibili in lingua inglese. Questo sprint è stato dedicato alla creazione di una collezione dati contenente registrazioni audio di interazioni umane in lingua italiana con un assistente vocale.
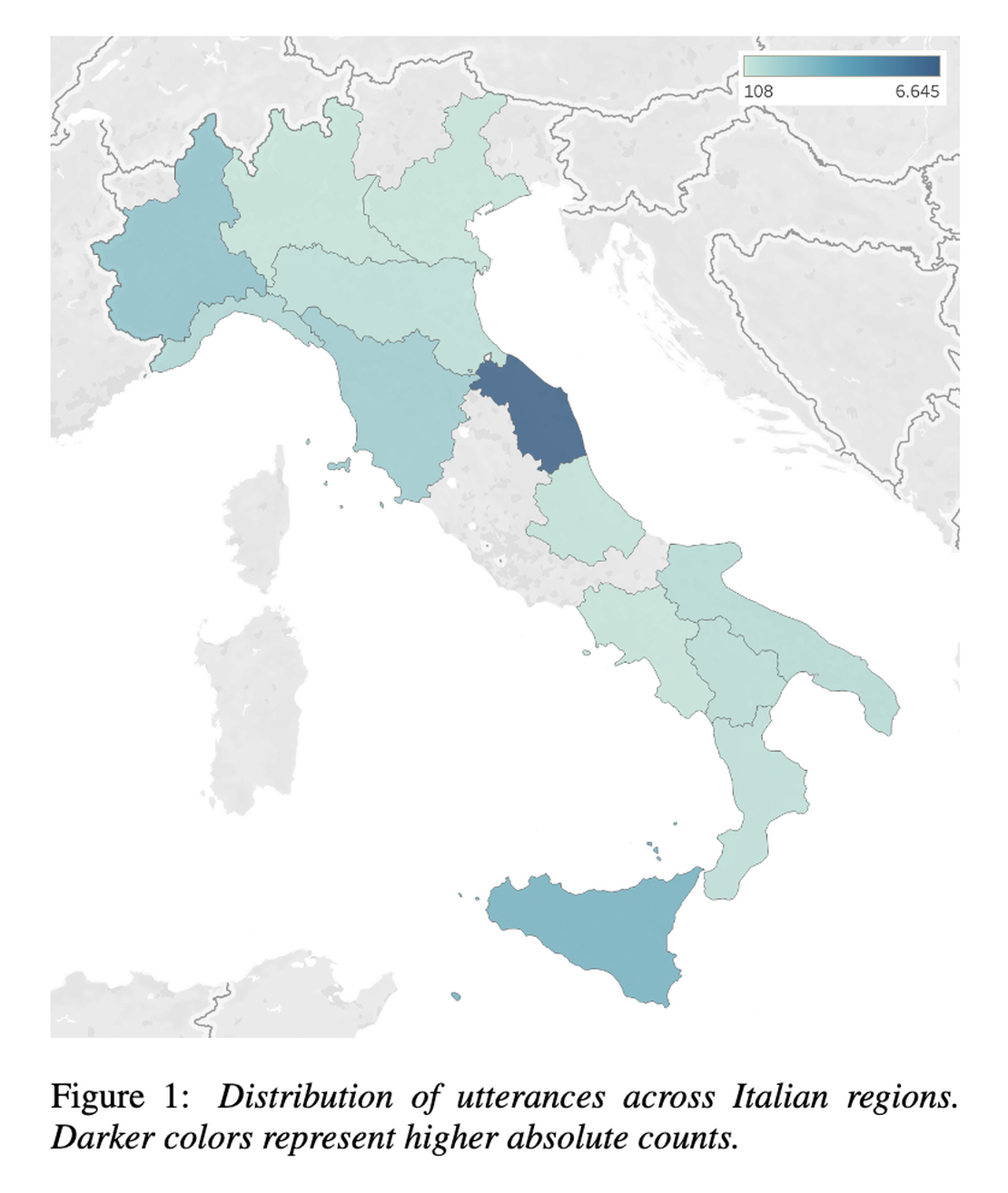
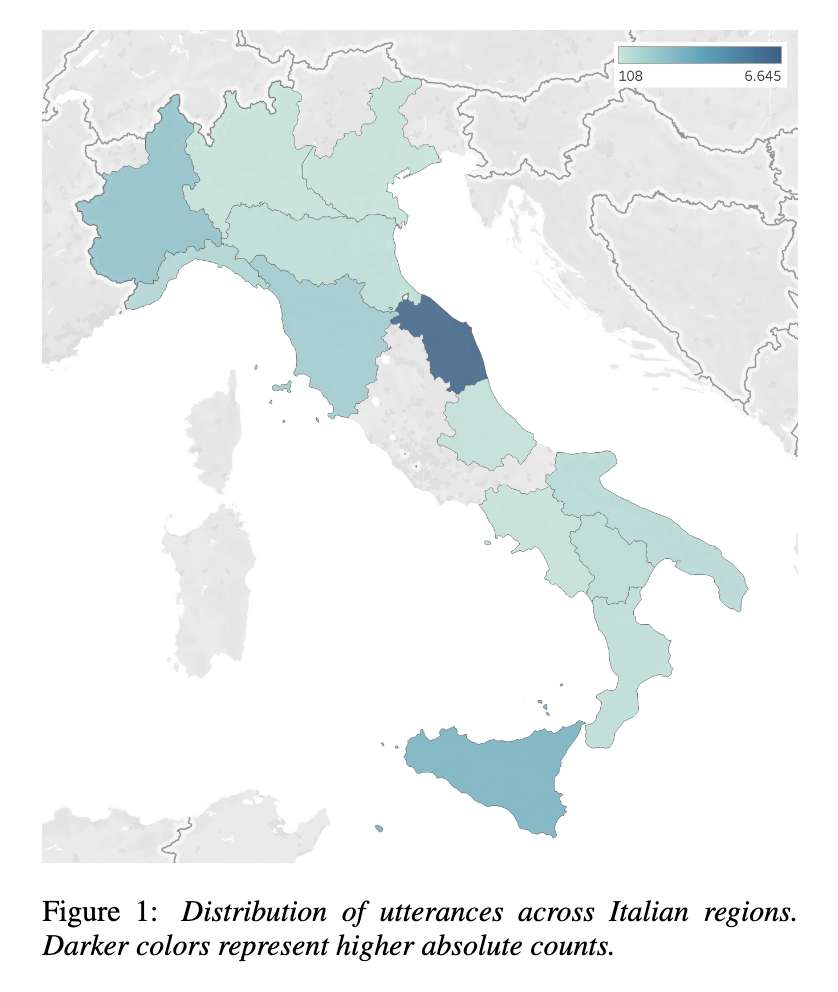
Il dataset si compone di più di 16000 registrazioni audio e copre una varietà di annotatori provenienti da diverse regioni italiane. Lo sprint ha avuto un duplice obiettivo: creare un dataset unico nel suo genere e la pubblicazione di un articolo scientifico (che troverete qui di seguito) per condividere i risultati con la comunità scientifica. Si ringraziano: Alkis Koudounas, Moreno La Quatra, Lorenzo Vaiani, Luca Colomba, Giuseppe Attanasio, Eliana Pastor, Luca Cagliero e Elena Baralis.
ITALIC: An Italian Intent Classification Dataset
Recent large-scale Spoken Language Understanding datasets focus predominantly on English and do not account for language-specific phenomena such as particular phonemes or words in different lects. We introduce ITALIC, the first large-scale speech dataset designed for intent classification in Italian. The dataset comprises 16,521 crowdsourced audio samples recorded by 70 speakers from various Italian regions and annotated with intent labels and additional metadata. We explore the versatility of ITALIC by evaluating current state-of-the-art speech and text models. Results on intent classification suggest that increasing scale and running language adaptation yield better speech models, monolingual text models outscore multilingual ones, and that speech recognition on ITALIC is more challenging than on existing Italian benchmarks. We release both the dataset and the annotation scheme to streamline the development of new Italian SLU models and language-specific datasets.
💾 Risorse utili:
- Collezione dati: Zenodo - Hugging Face
- Articolo
- Codice e risorse aggiuntive